Compute Storage Separate: A Case Study on AutoMQ
通过 AutoMQ 探讨存算分离如何降低云成本
存算分离的历史
存算一体是上一个时代大部分中间件设计的背景,十年前主流机器是 IDC 而不是一朵朵云,当时想要整出一个可以方便弹性伸缩的技术架构基本上是会被 IDC 层面限制死的。
存算分离是目前大环境降本增效的一个有力手段,再加上计算节点无状态化以后可以秒级扩缩容,云原生的技术团队经常有以下两个思路:
- 通过分层存储来做冷热数据分离,降低冷数据的存储成本。
- 通过存算分离避免数据频繁搬运,实现无状态节点的快速上下线。
本文拿 AutoMQ 作为存算分离的案例,分析 AutoMQ 如何通过存算分离做到弹性伸缩,降本增效。
AutoMQ 和 Pulsar
要讨论 AutoMQ 就避不开另外一个云原生当红炸子鸡 Apache Pulsar,这两个都是最近这几年比较云原生的消息队列实现。Pulsar 由 Yahoo 开源,是一个云原生的分布式消息流平台。它采用了计算与存储分离的架构,借助 Apache BookKeeper 实现了低延迟、高吞吐的消息持久化。
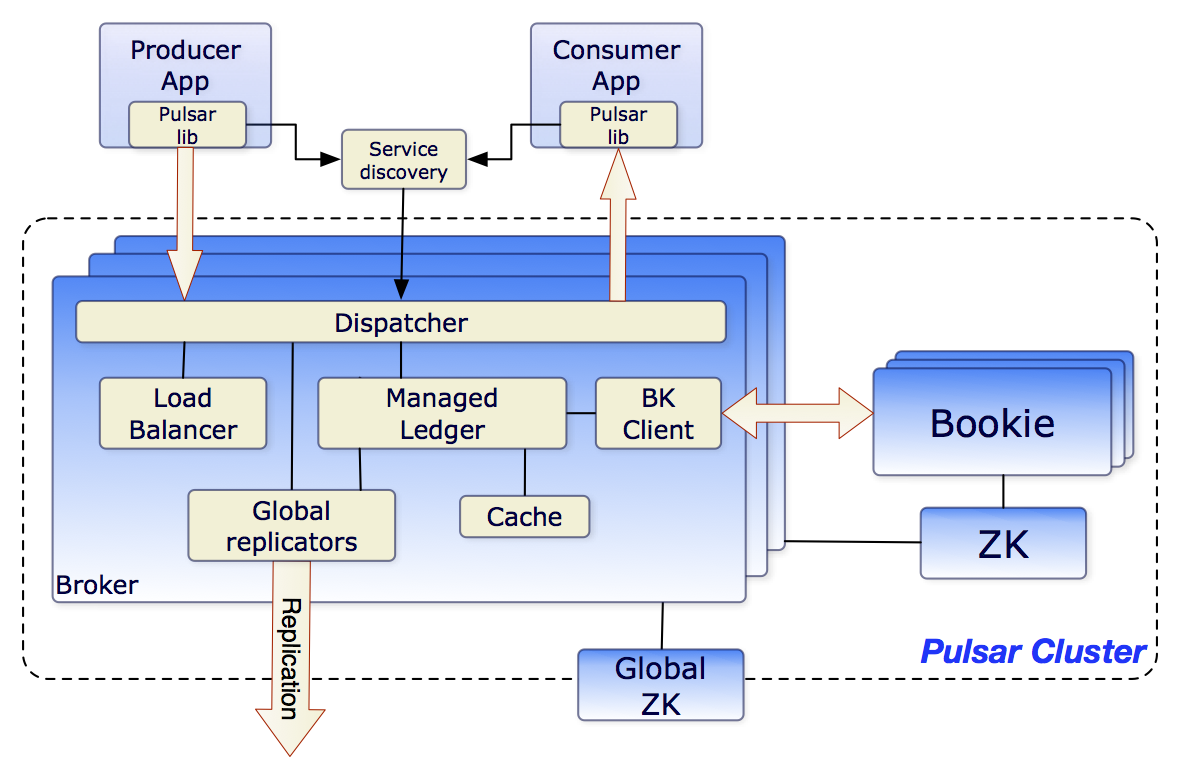
AutoMQ 是 RocketMQ 的团队做的,RocketMQ 自己在阿里内部也从 3.0 到 4.0 到 5.0 改变为云原生架构,但是这样的一个大项目,肯定是不如推倒重来更有效率的,就像淘宝的很多小二出去以后把拼多多做起来了一样,他们不是站在前人的肩膀上,而是站在自己的肩膀上。
从诞生的时间上看,Pulsar 比 AutoMQ 要早几年。但 AutoMQ 后发优势明显,AutoMQ 充分吸取了 RocketMQ 多年来的实践经验,同时也借鉴了 Pulsar 的设计思想,但直接采用了更加云原生的架构。
德国首相俾斯麦说 “loser learned from their own experience”,但不可否认,你如果自己踩过坑,肯定比学习别人的经验更加深刻,对不对?当然这没有考虑你自己的踩坑成本,实际上大部分成本是冤大头公司出的。
AutoMQ 如何实现存算分离?
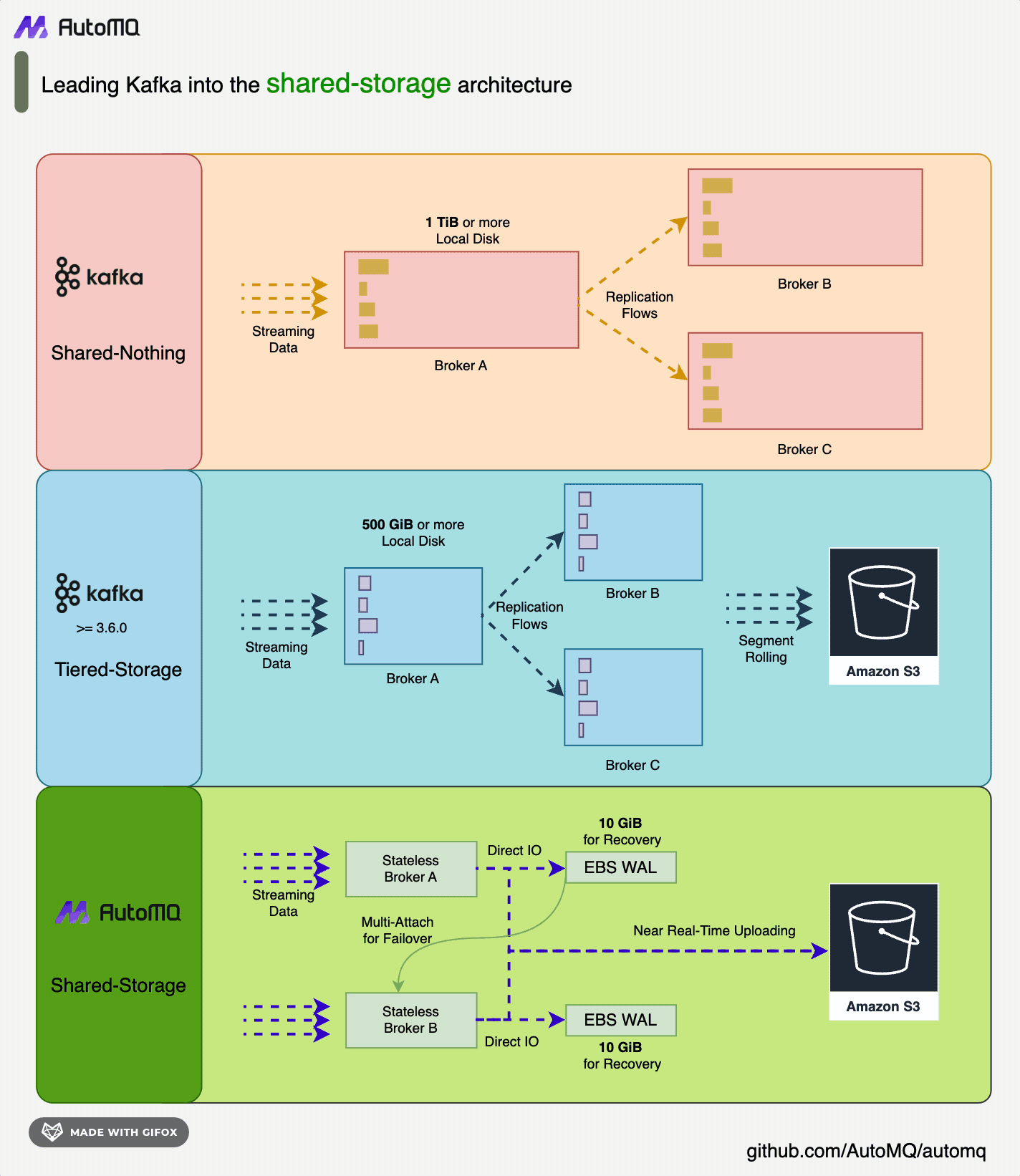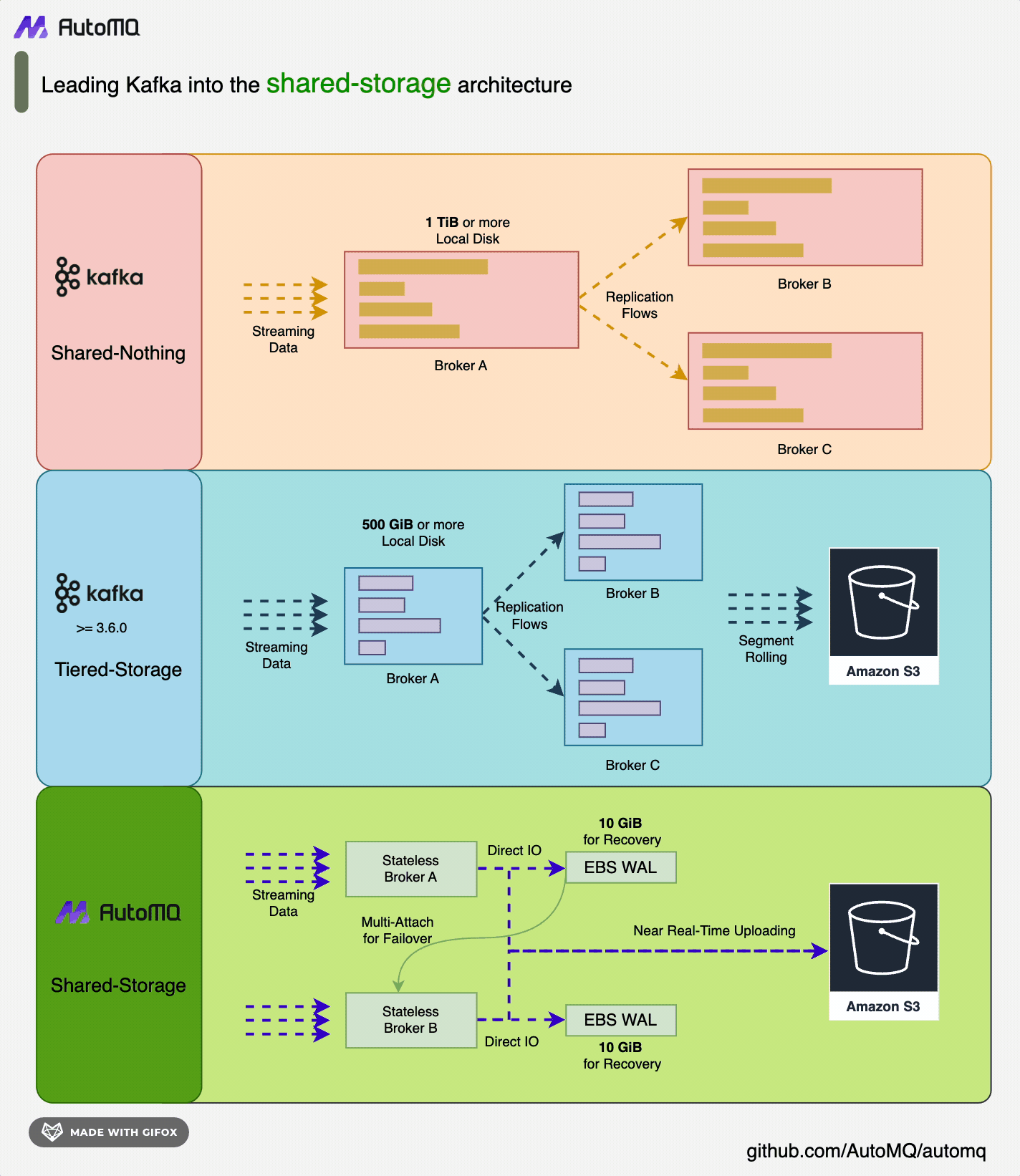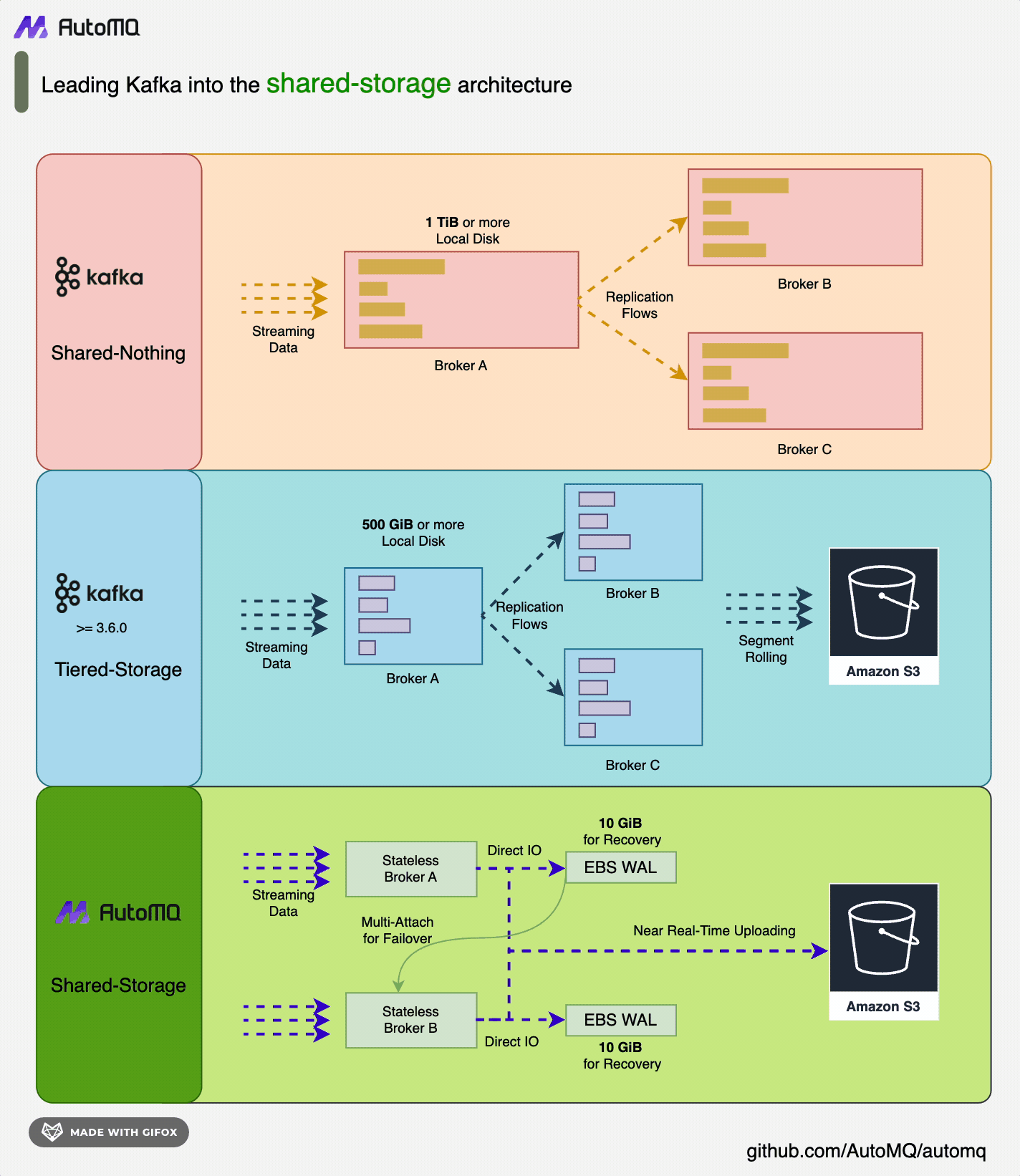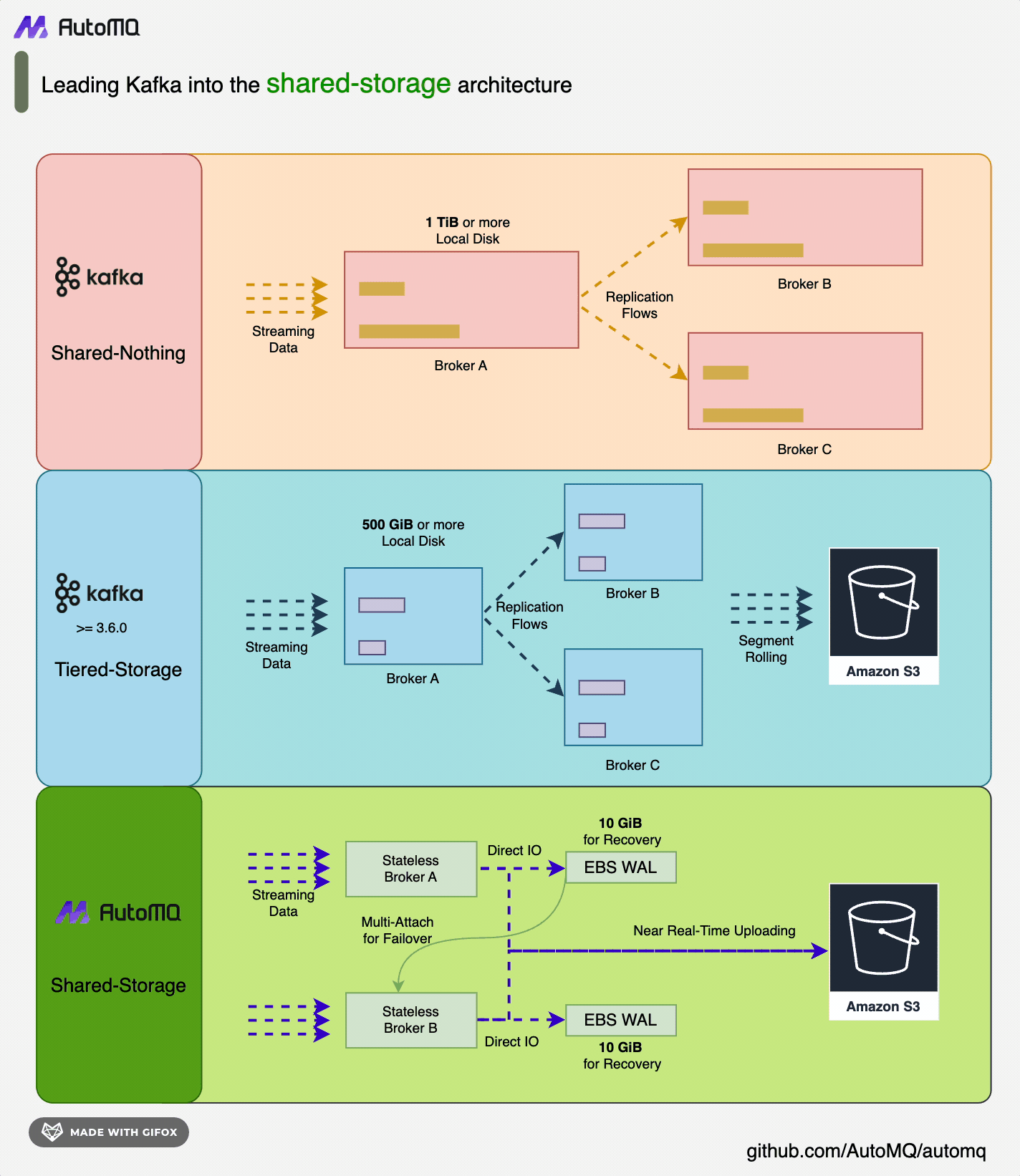
回到 AutoMQ 上来,RocketMQ 团队不仅踩在自己的肩膀上,还踩在 Pulsar 的肩膀上,因为 Pulsar 的架构复杂度更高,维护成本肯定更复杂,而 AutoMQ 把很多复杂度交给了云厂商。他们认为云原生的路线有一部分是云厂商原生,这样才能利用好云的基础设施,利用好云厂商的规模优势,所以 AutoMQ 没有类似 Pulsar 的 BookKeeper 的设计,也不用自己维护一个存储集群,而是用了 EBS 的特性做容灾和共享存储。
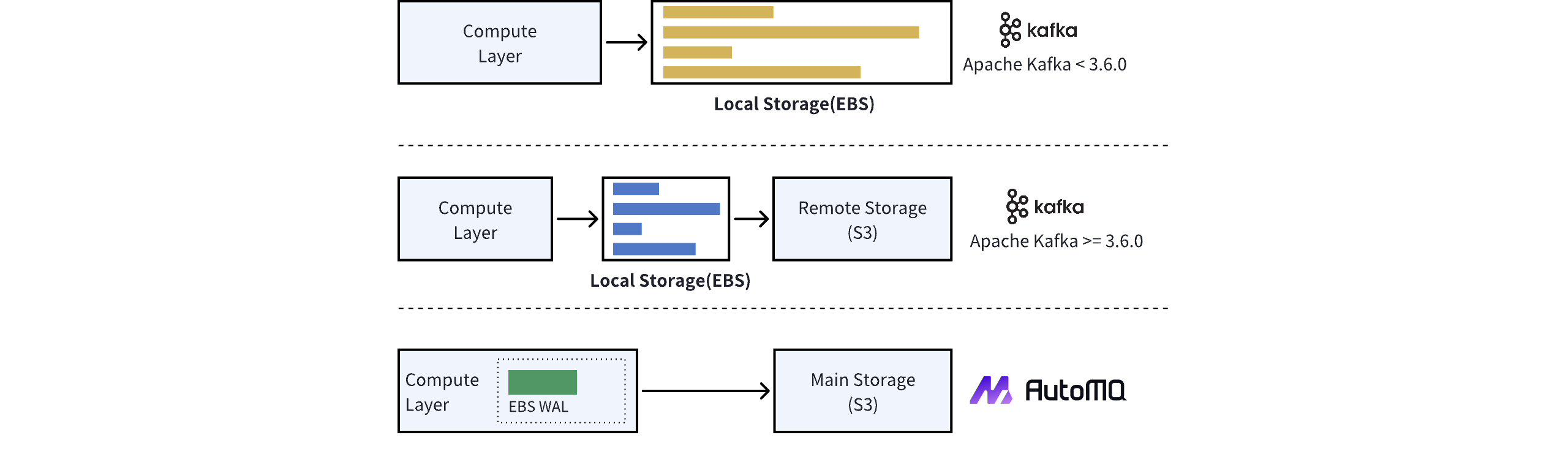
EBS 是用来做 WAL 的,这个 WAL 可以认为是 AutoMQ 架构里的 L3 Cache,不需要像 Kafka 的分层存储架构里的 500G 这么大,10G 就足够了,主要目的是实现容灾而不是存储海量数据。
WAL 是数据库系统中常用的一种技术,用于确保数据的持久性和一致性。它的核心思想是在对数据进行实际修改之前,先将修改操作记录到日志中。这样,即使系统在修改数据时崩溃,也可以通过重放日志来恢复数据。
在 MySQL 中,InnoDB 存储引擎使用了类似的机制,称为 redo log。redo log 记录了对数据页的修改,使得 MySQL 可以在崩溃后快速恢复数据,而不需要重新执行所有的 SQL 语句。
GreptimeDB,作为一个时序数据库,也采用了 WAL 机制。它使用 WAL 来提高写入性能和数据可靠性。WAL 允许 GreptimeDB 将多个写操作批量提交,减少磁盘 I/O,同时确保数据不会因系统崩溃而丢失。
AWS MemoryDB 的思路是基于类似 Aurora 的共享存储概念,把日志存放在远端共享存储中,这种做法虽然性能下降严重(仅有25%的性能),但确实是一种云原生 Share-Storage 的常见思路。好处是 LSM Tree 的 compaction 带来的性能下降也放到了远端,不会影响本机性能。同样的,GreptimeDB Edge 版本也推荐说 Edge 本地节点就不用 compaction 了,意义不大。
回到 AutoMQ 的情况,使用 EBS 作为 WAL 的存储确实是一个聪明的选择。它利用了云服务的优势,实现了高可用性和容灾能力,而不需要像传统方式那样维护大量的本地存储。10GB 的 WAL 空间对于缓冲写入操作和保证数据一致性来说通常是足够的。
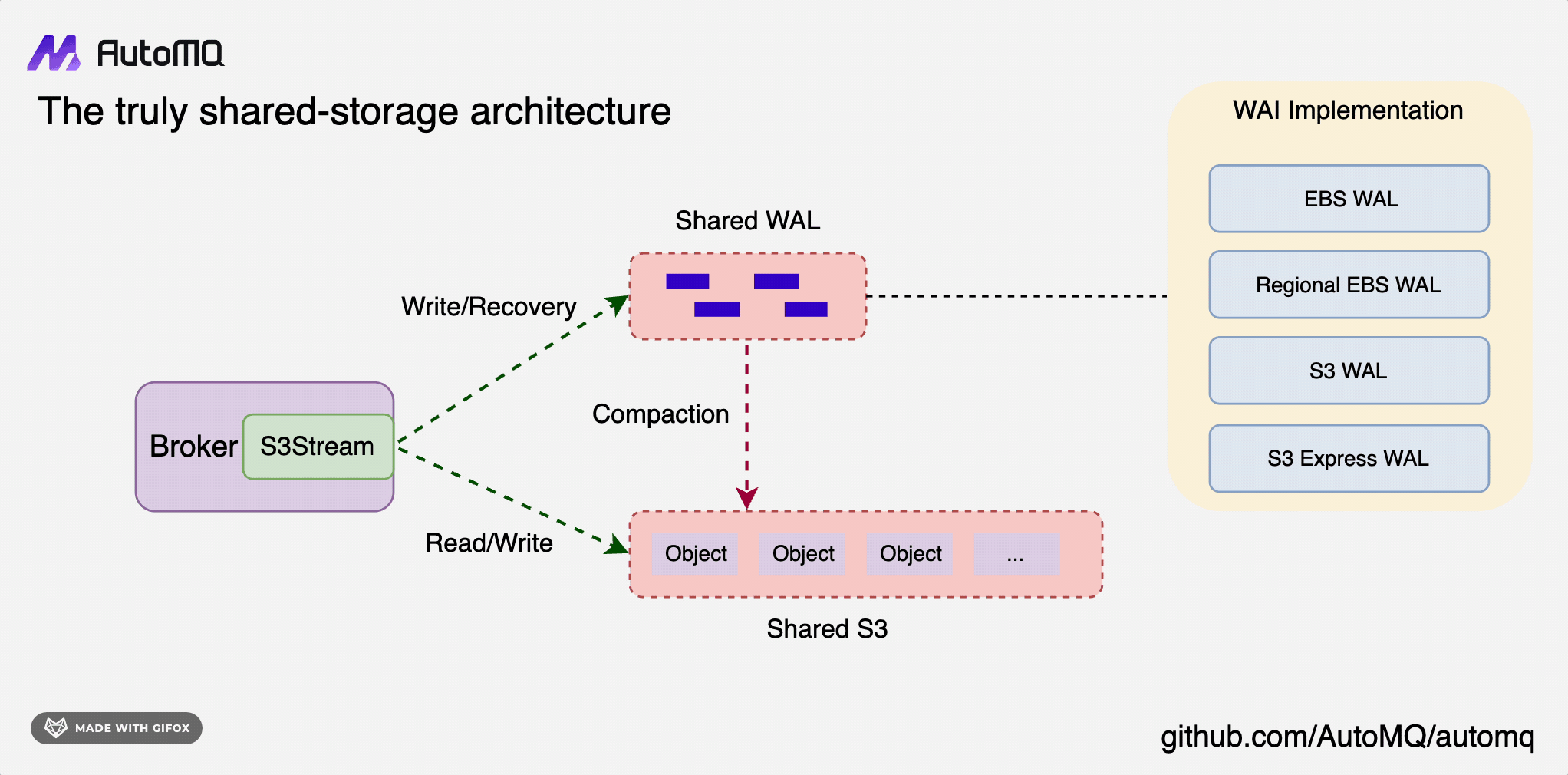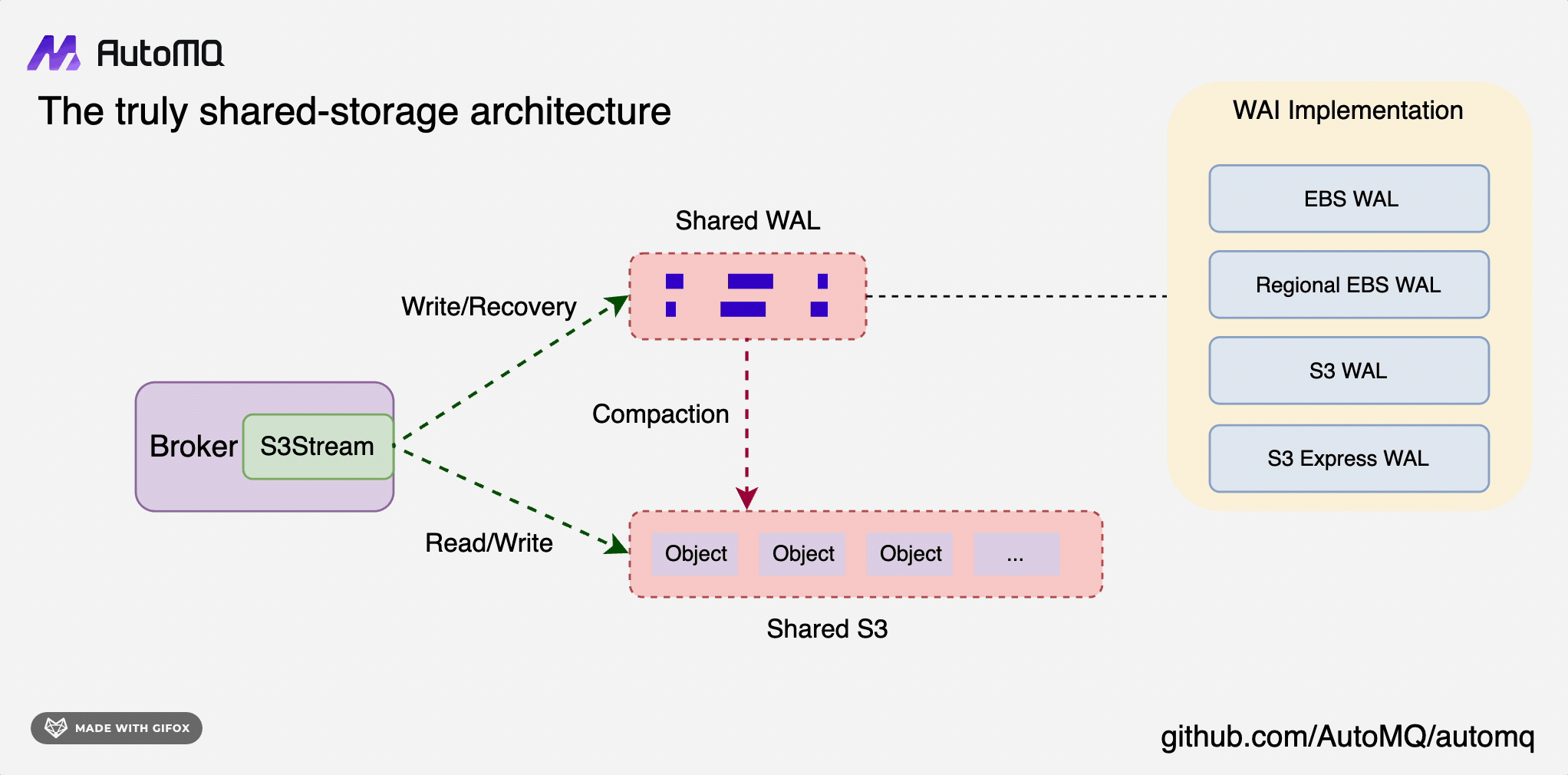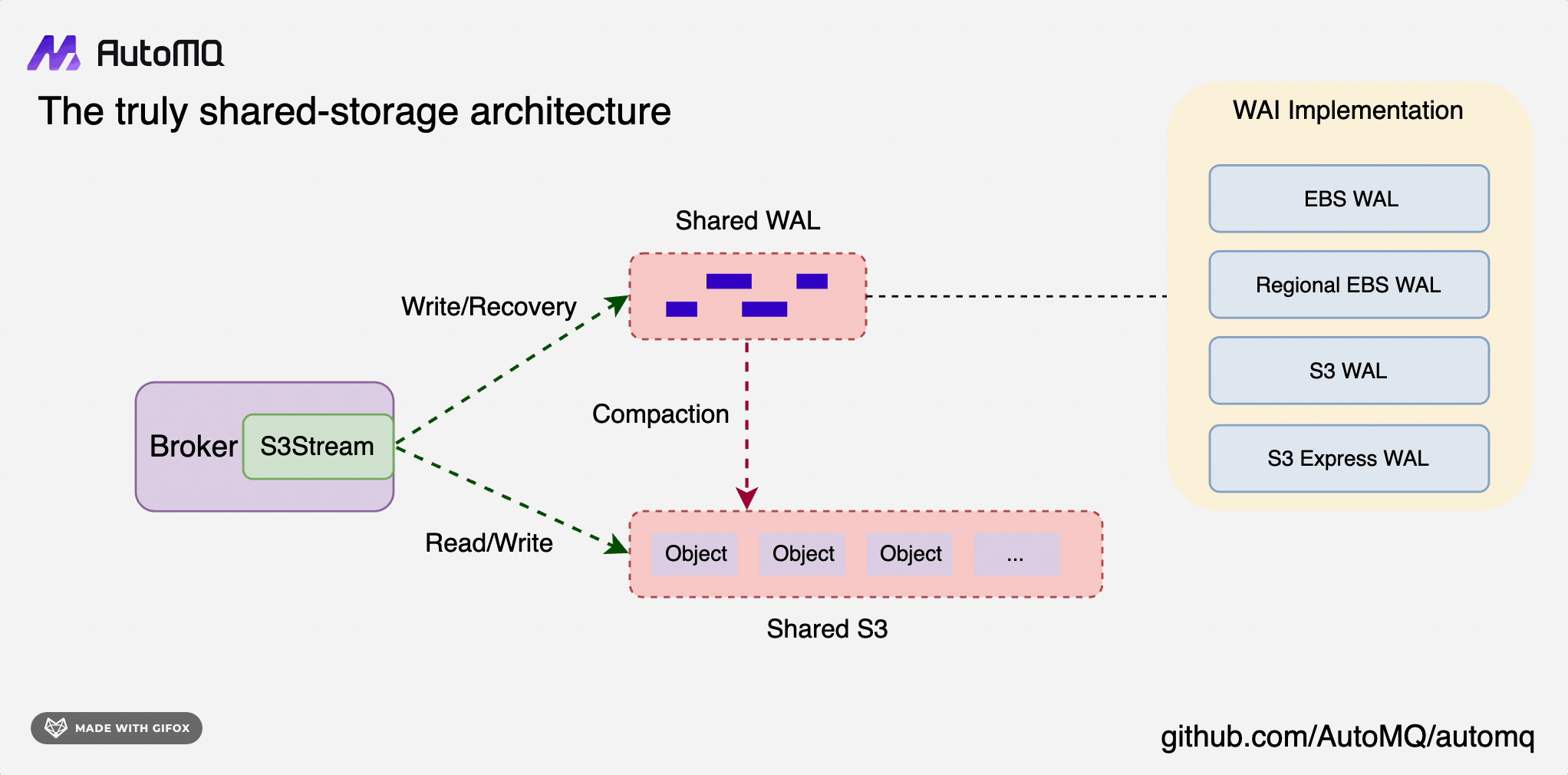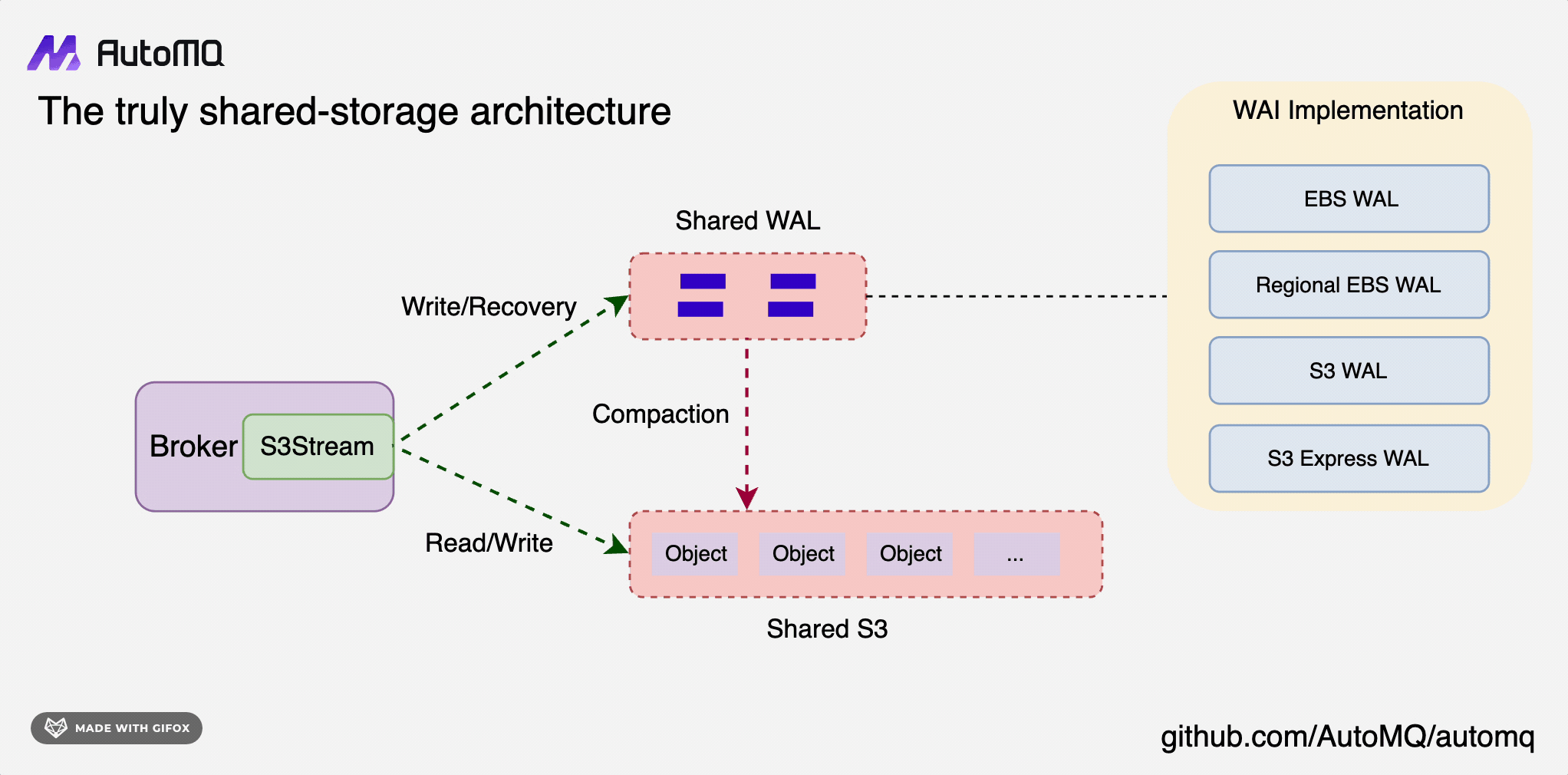
AutoMQ 通过利用 AWS EBS (Elastic Block Store) 的多重挂载功能来实现容灾和切换:
-
EBS 多重挂载: 数据冗余和高可用性的基础,云厂商(如 AWS)允许单个 EBS 卷同时挂载到同一可用区内的多个 EC2 实例上。
-
数据复制: 通过多重挂载,多个 AutoMQ 节点可以同时访问相同的数据,从 Kafka 的 Share-Nothing 变成 Share-Storage。
-
故障检测和切换: 当 Broker 节点发生故障或者需要扩容时,由于数据已经在 EBS 卷上并被多个节点挂载,新的 Broker 节点可以快速接管而不需要数据迁移。
-
跨可用区复制: 虽然 EBS 多重挂载限于同一可用区,但 AutoMQ 可能还实现了跨可用区的数据复制策略,以提供更高级别的容灾能力。
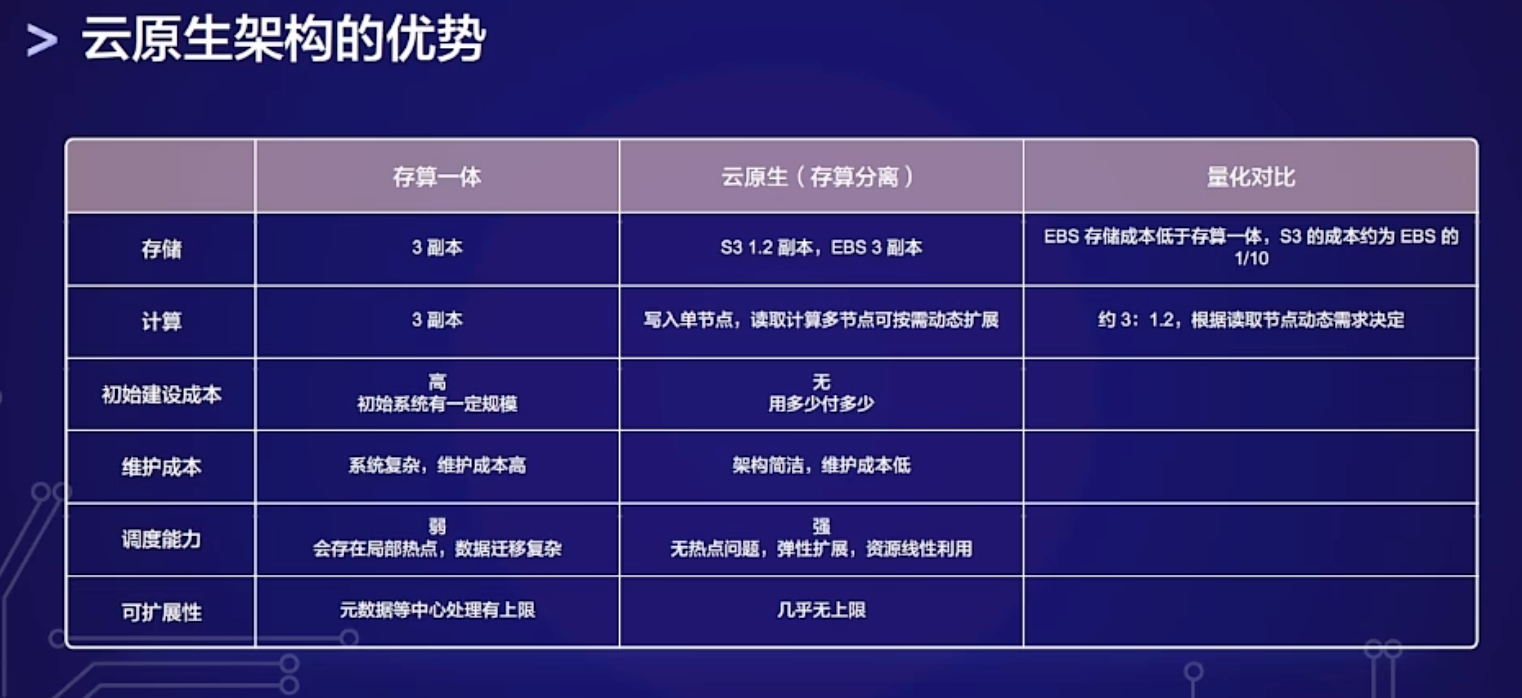
我在一个线下 Meetup 上问过他们,如果有的云厂商没有实现 EBS 的多重挂载怎么办?他们是否有 Roadmap 来自己实现 EBS 的存储分片和容灾?他们的回答是没有,因为这不是他们的发展路线,而且四大厂商都实现了多重挂载。(火山引擎不算)